Documentation pour les producteurs de données Theia/OZCAR
Flux de données depuis les observatoires jusqu’aux utilisateurs
Ce schéma décrit les flux de données depuis les systèmes d’information des producteurs de données en vert jusqu’au système d’information Theia/OZCAR en jaune de manière à rendre acessible les données à la fois pour les humains via un portail Web et pour les machines via des flux standardisés OGCs CSW et SensorThings.
Chaque observatoire gère ses données dans son propre système d’information. De part leur historique différent, les données des différents producteurs sont hétérogènes en terme de description et d’interopérabilité, de variables observées et de vocabulaire utilisé.
Pour arriver à standardiser et harmoniser les données et les fédérer dans un système commun, un modèle de données pivot basé sur des standards et un thésaurus commun ont été définis. Le modèle de données pivot permet de structurer l’information hétérogène et le vocabulaire contrôlé permet d’homogénéiser le vocabulaire des différents producteurs de données.
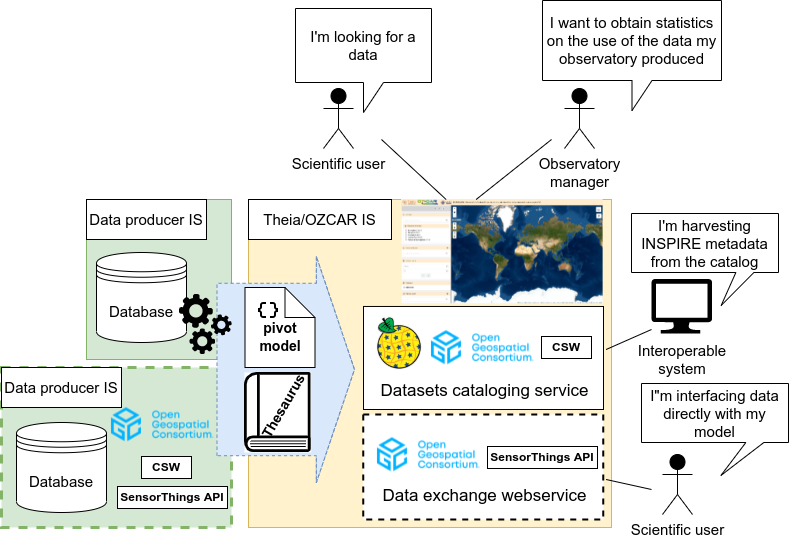
Diagramme de présentation général des flux du système d’information
Enrichissement des métadonnées à l’ingestion dans le SI Theia/OZCAR
Lors de l’ingestion des données des observatoires dans le SI Theia/OZCAR, un enrichissement des métadonnées des observations est effectuée. Cela concerne:
Entités administratives: à partir d’OSM
Climat : à partir de la classification de Köppen
Géologie : à partir du OneGeology (http://portal.onegeology.org), couche : World CGMW 1:50M Geological Units Onshore.
Altitude : à partir de SRTM 250 m
Noms des variables observées: les noms de variable producteur sont associés aux noms de variables du thésaurus Theia/OZCAR https://w3id.org/ozcar-theia
Comment ?:
Pour les entités administratives, le climat, la géologie et l’altitude: automatiquement par le workflow d’ingestion des données, sur la base des coordonnées des observations contenues dans le format pivot.
Pour les noms de variables: manuellement par les administrateurs du SI via une interface d’administration, post ingestion des données
Thésaurus Theia/OZCAR : catégories et noms de variables
Un vocabulaire contrôlé et hiérarchisé pour les catégories et noms de variables a été construit afin de proposer une recherche sur ces dimensions sur le portail. Il s’appuie sur la classification des catégories et noms de variables du Global Change Master Directory GCMD Science keywords, complété pour la chimie par la classification du SANDRE (Service National des Données et Référentiels sur l’Eau).
Le thésaurus Theia/Ozcar consiste en des concepts hiérarchisés de catégories variables couvrant les différents compartiments de la zone critique, où les noms de variables se trouvent au dernier niveau de la hiérarchie. Une vue de l’arborescence des catégories de variables du thésaurus Theia/OZCAR est disponible: Arborescence des catégories de variables du thesaurus Theia/OZCAR.
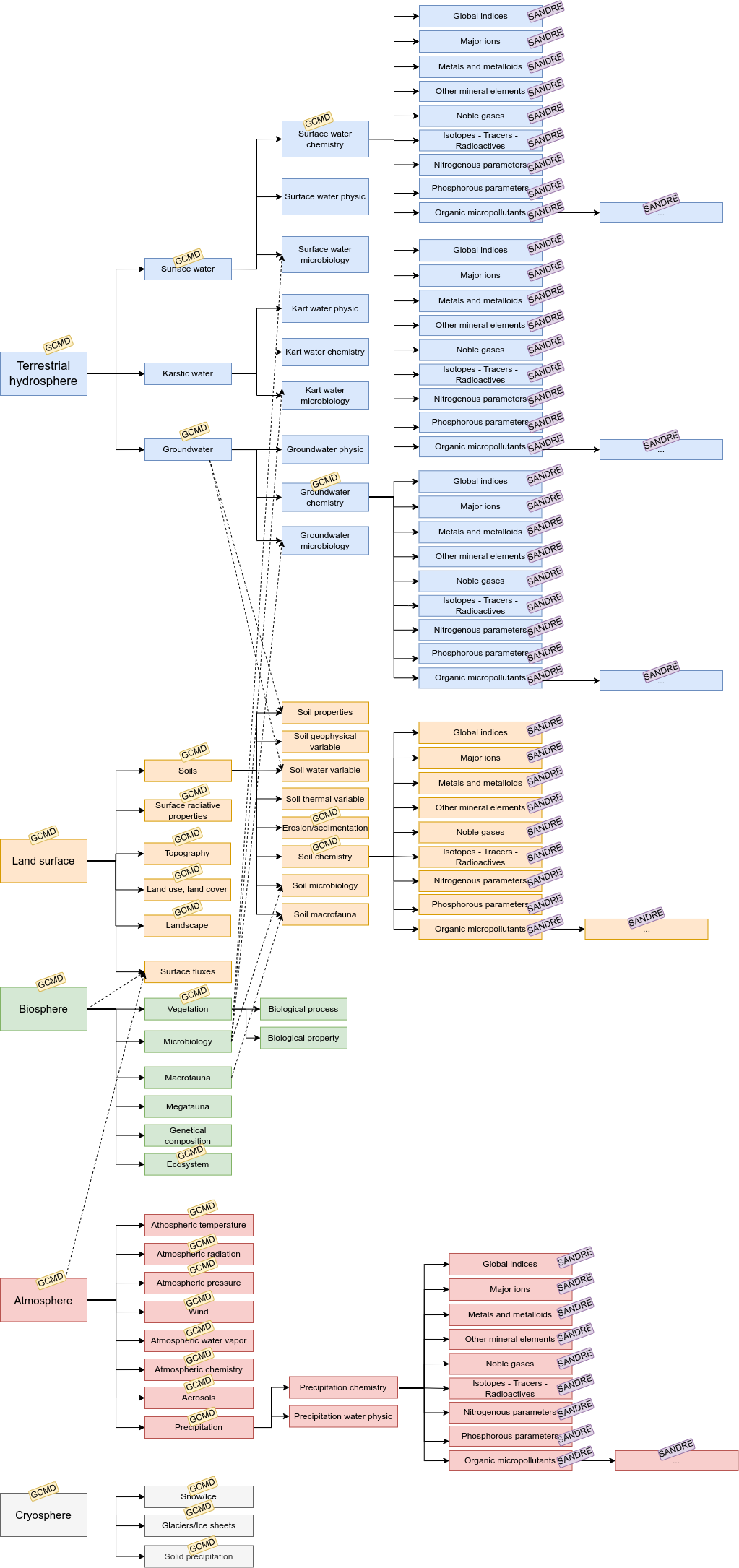{kind=link}
Le thésaurus a été formellement décrit en SKOS et ses concepts seront alignés avec des concepts identiques ou similaires de thésaurus thématiques internationaux (FAO AGROVOC, GEMET, EnvThes (LTER), ANAEE,….).
Le thésaurus Theia/OZCAR est publié sur le Web en Linked Open Data: https://w3id.org/ozcar-theia. Il implemente désormais la recommendation RDA I-ADOPT pour la descriptions des variables observés par les producteurs de données.
Dans le modèle de données pivot, les producteurs de données doivent spécifier l’URI d’un ou plusieurs catégories de variable auxquelles leurs noms de variables se rapportent. Ces catégories doivent permettre d’identifier le compartiement de la zone critique dans lequel est réalisée l’observation. Le mapping entre les noms de variable producteur et noms de variables Theia/OZCAR sera réalisé par les scientifiques en charge du système d’information Theia/OZCAR après l’import des données dans le système. Si la variable du producteur de données est déjà décrite avec une précision suffisante par un concept du thésaurus Theia/ OZCAR, le producteur peut référencer ce concept à la place d’une ou plusieur catégorie de variable.
Modèle de données pivot
Modèle de données pivot: diagramme de classe
Pour permettre l’échange d’information entre les producteurs de données et le SI Theia/OZCAR, un modèle de données pivot commun a été construit sur la base des standards ISO19115/INSPIRE, O&M et DataCite. Il permet de véhiculer les métadonnées nécessaires aux fonctionnalités du portail Theia/OZCAR et à l’implémentation de services d’interopérabilité et de déclaration de DOI.
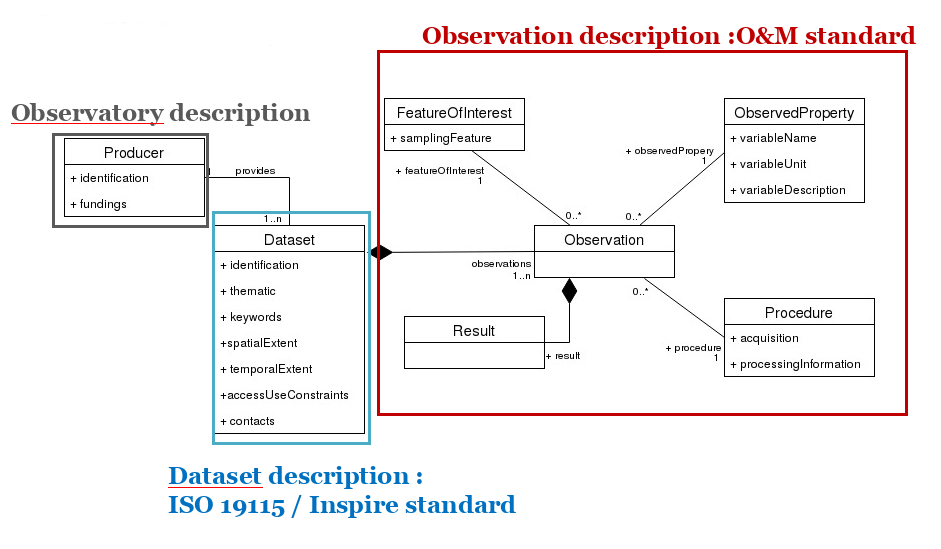
Diagramme conceptuel du modèle de données Theia/OZCAR
Diagramme UML du modèle: Diagramme de classe du modèle.
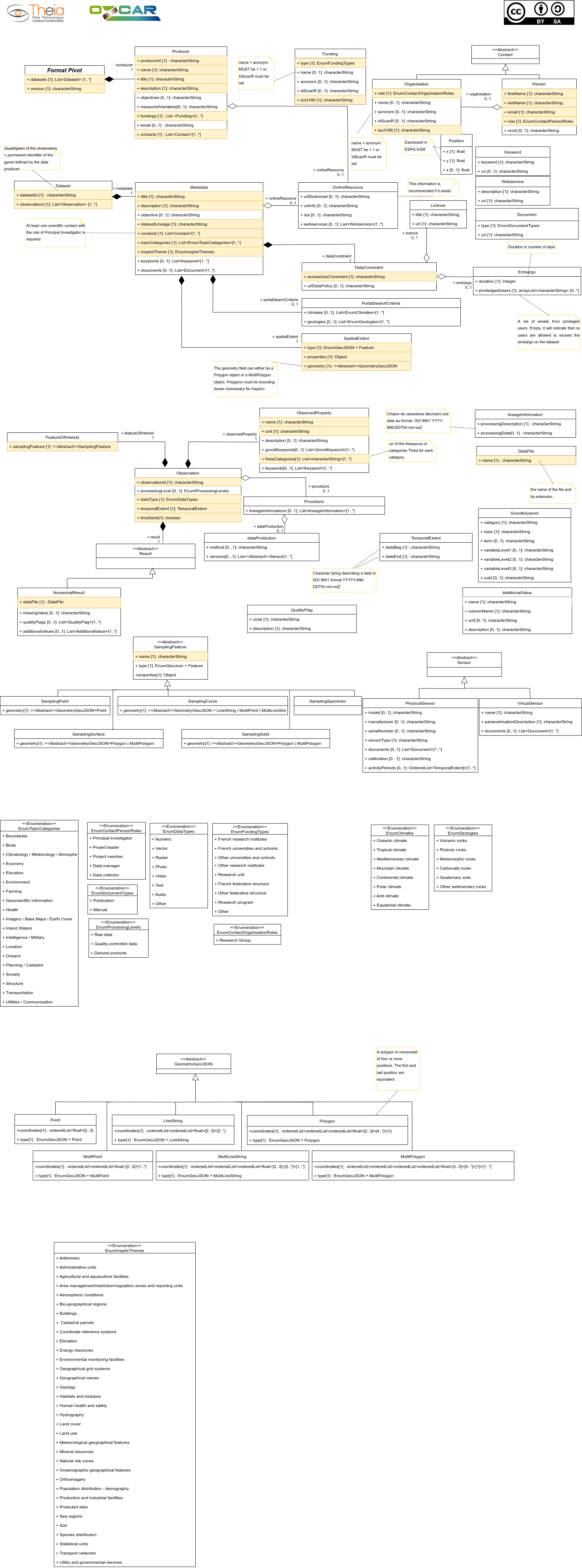{kind=link}
Modèle de données pivot: description et implémentation en JSON
Le modèle pivot doit être implémenté en JSON/GeoJSON selon la specification suivante: Fichier PDF de description de l'implémentation JSON du modèle pivot.
Un exemple d’implémentation du modèle pivot pour le producteur de données AMMA-CATCH (le fichier ne contient qu’un seul jeux de données sur les 38) est fourni: Fichier .json exemple pour le producteur AMMA-CATH contenant 1 seul jeux de données.
Un exemple d’implementation du modèle pivot renseignant tous tous les champs optionnels et disponible ici: Fichier .json exemple avec tous les champs optionels.
Test de conformité du fichier JSON:
Pour tester la conformité du fichier JSON avant dépôt, un webservice est disponible. Le webservice utilise les schémas JSON en ligne: https://in-situ.theia-land.fr/json-schema/
Pour valider le fichier .json lancer la ligne de commande suivante:
curl -i -v -XPOST -F "json=@<PRODUCER_ID>_en.json" https://in-situ.theia-land.fr/api-validation/validate
Modèle de données pivot: format des fichiers de données
Les données doivent être fourni selon la spécification suivante: Fichier PDF de description des fichiers de données.
Procédure de dépot des données et métadonnées
Le fichiers de métadonnées JSON et les archives ZIP des données doivent être déposés sur le serveur du SI Theia/OZCAR sous la forme d’une « fat » archive ZIP selon la procédure suivante: Fichier PDF de la procédure de dépot des informations.